



I once sat across a conference table from the venerable Ron Arkin. Professor Arkin is a renowned roboticist at Georgia Tech and he has been involved in conversations about AI ethics before it was called “AI ethics.” Arkin has been an important voice in what was often called “robot ethics” and especially in the debate over the ethics of lethal autonomous weapons systems. He’s on the side that says that AI-enabled robots will be immune to many of the human factors that result in war crimes. Robots don’t get hungry or thirsty or tired. They don’t hate the enemy and they (mostly) do what they’re told. So, perhaps robots will perform morally better on the battlefield than their human counterparts. Arkin writes,
The status quo with respect to human battlefield atrocities is unacceptable and emerging technology in its manifold forms must be used to ameliorate the plight of the noncombatant.
Somehow, back in 2017, I found myself at a small workshop on the ethics autonomous robotic systems at the University of Zurich in Switzerland. (If you are interested, that series of workshops culminated in this report on how to evaluate the risk of robots in the security context). At that early workshop, though, I was an AI novice. I had been invited because I had an operational background in remotely piloted aircraft, not because I knew anything about AI.
So, there I was, sitting across the table from Ron Arkin. He talked about programming an “ethical governor” into lethal autonomous weapons systems. “But Ron,” I asked in the impetuousness of youth, “how could you possibly program an ethical governor given that AI is a “black box,” the inner workings of which are opaque to its designers?” (Ok, I probably didn’t phrase it exactly like that, but that was the gist).
In machine learning—the kind of AI that has become popular since about 2012—the neural network can be so complex that even the developers who design and train it are unable to trace how the system moves from input to output.
The Georgia Tech professor looked at me and blinked for what felt like several minutes, but what was probably a much more socially acceptable period of time. “You know, Joe,” he said, “not all AI is a black box.”
Back then, I just had no idea.
You see, there is a history of AI that comes before the machine learning revolution that began in 2012 and certainly before large language models like ChatGPT, Claude, and Gemini.
So, what is that history and why should we care? One reason is that if we don’t understand the history of AI, we won’t be able to understand why people started talking so much about “AI ethics.” But another is that if we skip over the history of AI before the deep learning revolution, we’ll fail to understand what might be possible by combining modern deep learning with “good old fashioned AI.”
Here in this post, though, I don’t want to tell you the history of AI. I want to show you.
I’m going to use a tool called Google n-gram and if you’ve never used it, it needs a brief introduction. (If you have used it, feel free to skip down a few paragraphs).
If you’ve ever visited Google Books, you know that Google has digitized millions of books. In so doing, not only did Google scan and upload images of each page, but they made the text of each page searchable. What this means is that if you visit the site, and if you search for the sentence,
“I once had my nose broken in a fight in which I was an unwilling participant”
you should find my book (that’s a story for another day).
One implication of this mass digitization and ability to search is that Google can now show you the prevalence of any search term you’re interested in throughout the entire digitized corpus over time. So, before we get into the visual history of AI, let’s look at a quick example to see how the tool works.
Suppose we were to search for references to “President Bush.” I would expect to see references to begin during George H. W. Bush’s presidency (1989-1993). Then I’d expect to see another spike during George W. Bush’s presidency (2001-2009).
That’s exactly what we find:

Onto the history of AI. Now let’s search for the terms “artificial intelligence,” “expert systems,” “machine learning,” and “AI ethics.”
I’ve set the time window from 1955 to 2018. I chose 1955 because that’s when John McCarthy coined the term, “artificial intelligence.” and 2022 is the most recent Ngram data available. I’ve chosen 2018 because I’ve been showing this chart to audiences for some time and for the last several years, the Ngram data was only available through 2018. You’ll see why that matters in a moment.

There is so much to love in this chart, but let’s start with the bump in the middle. Historians of AI like to describe its history in terms of summers and winters. An AI summer is characterized by growth and hype—lots of interest, lots of research dollars, lots of technological development, and as we can see in the Ngram data, lots of references in major publications. That bump in the 1980s-90s is the second AI summer.
The first AI summer was in the 1960s and it was largely contained within academia. But it was followed by an AI winter—a period during which the rate of technology development plateaus, users and investors become disillusioned, research money dries up, and as a result, people stop talking about it as much in books and in the press.
The second AI summer is in the 1980s and 1990s and you can see that in the chart. "Artificial Intelligence” is marked by the blue line. There is a huge rise in people writing and publishing on artificial intelligence that corresponds to that period of increased capability and increased research funding.
And look at the green line that is tightly correlated with the blue line during the 1980s and 1990s. That green line represents the search term, “expert systems.” You see, during the second AI summer, no one (ok, very, very few people) were talking about neural networks. At that time, the real increases in capability—and the corresponding hype—were focused on “expert systems.” These are deterministic software programs based on if/then logic statements and designed based on inputs from experts in the relevant field.
Now follow me to the second big spike in references to artificial intelligence. This one begins in about 2015. This time, the spike in references to artificial intelligence is not accompanied by an increase in references to expert systems (green line) but it is accompanied by an increase in references to machine learning (red line).
The third AI summer—the period we are in right now—is a period of rapid capability development in machine learning. This is the heyday of the neural network.
Now that we can picture these three AI summers—first in the 1960s, then again in the 1980s and 1990s, and finally in our own time, beginning in about 2015—let’s look at AI ethics.
As you might suspect, even though AI ethics is a popular topic these days, references to AI ethics appear far less frequently than references to AI more generally. So let’s look at the Ngram data for “AI ethics” by itself.
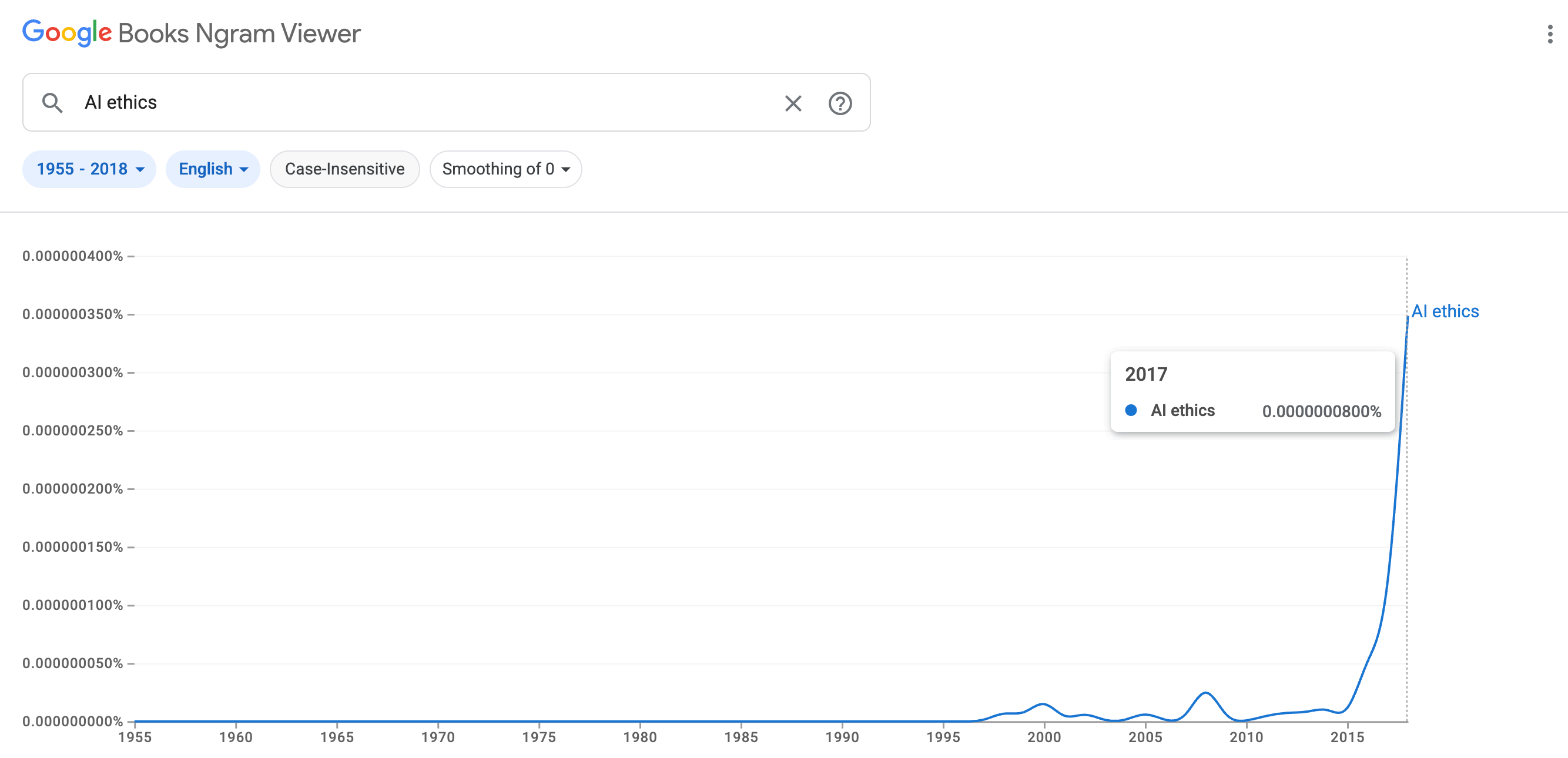
Even if, in sheer numerical terms, there are fewer references to AI ethics than to AI more broadly, there is no question that references to AI ethics increase dramatically beginning in about 2015. Now, here’s the best part: Look at the timeframe of the second AI summer, the 1980s and 1990s. There is no perceptible increase at all in references to AI ethics.
I’m an academically trained philosopher and I will be the first to admit that correlation does not imply causation. But there is a phenomenon here that cries out for an explanation. Somehow, there was a two-decade period of AI development during which no one seemed to care about AI ethics. And now there is another period of AI development in which lots and lots of people care about AI ethics.
One plausible explanation for this phenomenon (and I think it is the right one) is that deep neural networks raise ethical questions that the deterministic expert systems of the 1980s and 1990s just didn’t raise.
What is it about machine learning that raises ethical questions? One simple way to capture it is that machine learning generates uncertainty and unintended consequences that expert systems did not.
It’s not that expert systems never erred. Any technology is subject to fail and if someone tries to tell you they’ve built a technology that never fails, hold on to your wallet! But when expert systems fail, they fail in ways that are understandable to the human expert. Why? Because the system was designed to emulate human decision-making.
In machine learning, by contrast, we’re enabling the model to identify patterns in the training data that correspond to the desired output whether those patterns would be important to a human or not.
Figuring out what traits in a job candidate are important for a specific job is hard work. Coding that multivariate equation into an expert system would be extremely difficult. But suppose I didn’t have to identify the skills I need for a job. Suppose instead that I just load thousands and thousands of resumés into a training dataset and then ask a deep neural network to figure out which patterns of words in the training data are most closely associated with the resumés that resulted in a job offer?
That’s what Amazon tried to do in 2015. The problem was that, historically, Amazon did in fact hire more men than women. So the training data they used to train the model was biased toward men. The end result was that, even though none of the developers intended to build a hiring algorithm that was biased against women, they did in fact build a hiring algorithm that was biased against women. (Amazon recognized the error and scrapped the project before it went to production).
There are several high-profile cases like this one that caused AI researchers to recognize that machine learning imposes uncertainty and unforeseen consequences that previous generations of AI hadn’t raised. That’s where the whole field of AI ethics comes from. And that’s why, on my view, “AI ethics” starts to spike in the Ngram data (~2015) just a couple of years after “machine learning” starts to spike (~2012).
I promised I’d tell you why I cut the Ngram data off at 2018. When I used to show that chart to people back when the data was available only through 2018, it looked as if the third AI summer (our current time) was roughly commensurate with the second. In other words, it looked like the references to AI now were about as frequent or as prominent as references to AI in the 1980s and 1990s had been; but no longer.
Here’s the Ngram data through 2022:
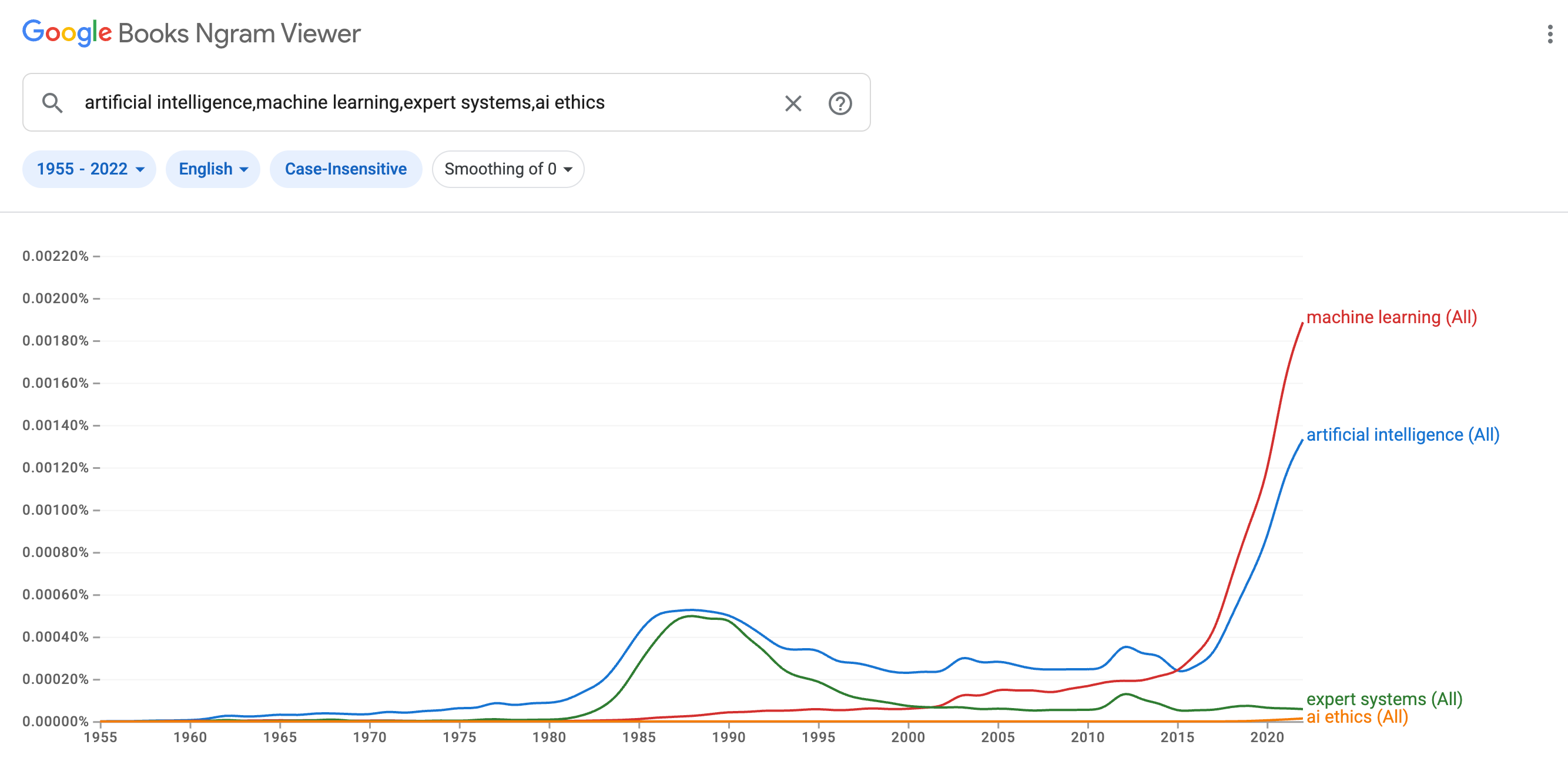
Our current third AI summer makes the second AI summer of the 1980s and 1990s look more like a molehill than a mountain. The rate of technological development we have seen in AI over the last 5-10 years really is unprecedented.
But be careful. Just as there were limitations that expert systems could not overcome (thus, the second AI winter), there may be limitations that deep neural networks cannot overcome.
Hallucinations might be one of these limitations. Researchers are trying as hard as they can to eliminate (or even to reduce) hallucinations, but they haven’t solved it yet. This may end up being an inherent limitation in deep neural network performance.
A more intrinsic challenge may be that beyond a certain size and model complexity, increases in scale produce diminishing returns. For years, AI companies have sought to increase model performance by providing ever more data, ever more computing power, and ever larger parameter counts in their models. There are some who suggest that we are approaching the limits of that trend. Like Will Parker says of Kansas City, maybe the big AI companies have “gone about as fer as they can go.” For many, this sounds like sacrilege—given AI’s rapid growth in performance, how can we even imagine a plateau any time soon? But that’s exactly what the researchers in the 1980s and 1990s thought before the second AI Winter.
I offer two thoughts to close, one small and one bigger. First, we have crossed a kind of Rubicon in AI development. This AI summer far surpasses the last one. But that really shouldn’t come as a surprise. NVIDIA, the leader in the chips that make machine learning possible, has a market cap of two point seven trillion dollars. Sam Altman is reportedly raising trillions of dollars to manufacture the next generation of chips to power machine learning training and inferencing. This AI summer is just bigger than the last one.
But there’s a second way to view this trend. For years, historians told the story of AI in terms of these boom and bust cycles—but there were only two and a half cycles to look at. The 1960s was real, but small. The 1980s and 1990s was considerable, but small-ish (at least in hindsight). Now we are in the middle of another boom.
Maybe the trend we should notice isn’t just a cyclical one of summers and winters, but a progressive one in which each boom is bigger than the last.
I don’t know whether the current interest in large models, self-supervision, and transformer architectures will fizzle. But if it does, the AI researchers will ask the question they have asked since 1955: What’s next?
Credit Where It’s Due
There are a couple of books I can commend to you on this topic. My favorite is A Brief History of Artificial Intelligence by Oxford Computer Science Professor Michael Wooldridge (Flatiron Books, 2021). It’s the most accessible and approachable history I’ve read (and, for good measure, Professor Wooldridge was kind enough to join my AI elective virtually to discuss the history with my students!).
For a story that gives greater emphasis to the cast of characters that made AI possible over the decades, you might also appreciate Cade Metz’s Genius Makers (Dutton 2021).

As always, the Views Expressed are my own and do not necessarily reflect those of the US Air Force, the Department of Defense, or any part of the US Government.